GAN学习笔记
参考资料
开山之作:https://arxiv.org/pdf/1406.2661.pdf
GAN lab: https://poloclub.github.io/ganlab/
教程:https://arxiv.org/pdf/1701.00160.pdf
DEMO:https://zhuanlan.zhihu.com/p/24767059
笔记参考:https://zhuanlan.zhihu.com/p/84783062
DCGAN: https://ar5iv.labs.arxiv.org/html/1511.06434
Spectral GAN: https://arxiv.org/abs/1802.05957
Conditional GAN: https://blog.csdn.net/qq_24224067/article/details/104293409
为什么学习生成模型?
首先了解什么是生成模型,以及为什么要学习生成模型。回顾机器学习的定义,机器学习的任务是要学习事物的内在规律(分布),并做出预测。按照监督性学习的模式,比方说有一个人脸,我想让机器识别这个人脸的特征,并且通过与label关联(比方说这是谁)从而能够进行人脸识别,下次再看到一张脸可以输出识别率。
生成模型也是对人脸的特征进行学习,但是我的任务现在不是人脸识别,而是生成人脸,这在现实环境下有很大的应用场景,比方说把糊掉的照片修复,比方说通过勾勒线条生成好看的图,比方说智能P图等等。但是除了这些应用,生成模型还有更多的应用场景。
- 从生成模型中训练和抽样是对我们表示和操纵高维概率分布能力的极好测试。这对数学和工程领域帮助很大。
- 生成模型能够生成对未来场景的预测,是基于模型的强化学习的一个很重要的组成部分。
- 生成模型适用于半监督学习场景 - - 有很多缺失label值的学习场景,因为它能够生成对应输入数据的label。
GAN原理
我们想要模型能够生成和采样图片特征相似的图片,为此我们需要训练一个好的生成器,那么什么样的生成器才能叫“好的”呢?我们假设某种类型的图片张量是服从高维分布的的,设为
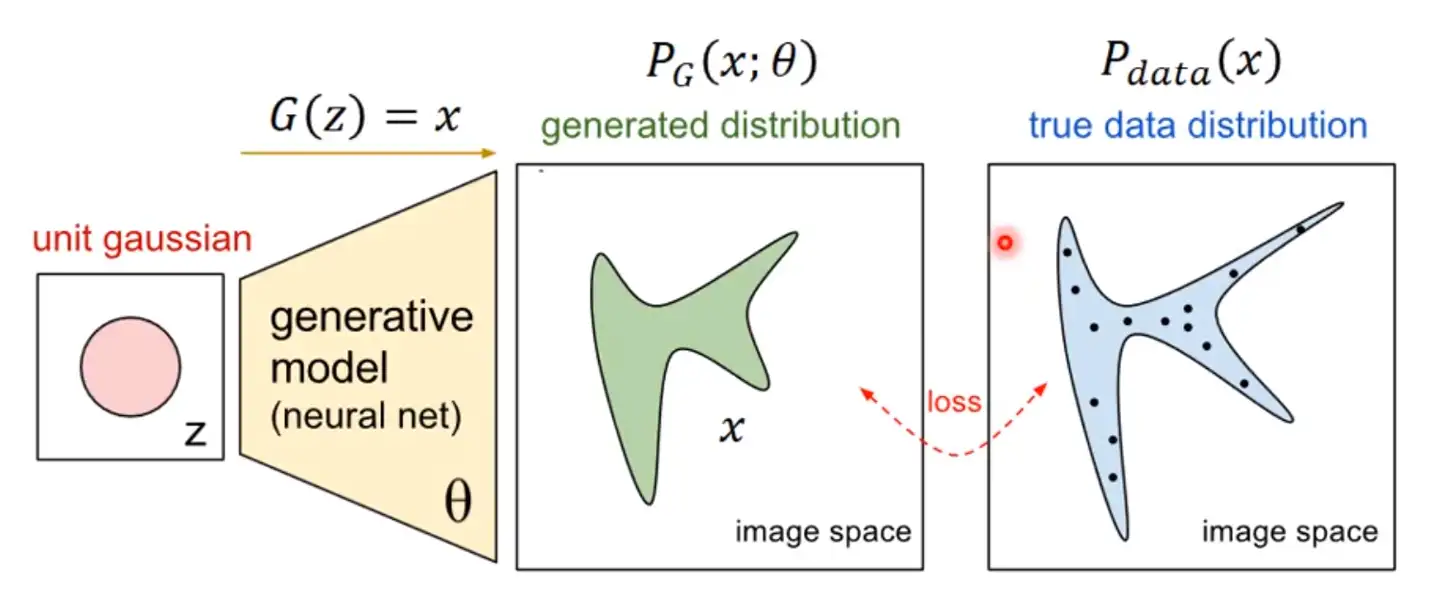
这个过程可以用下面的数学公式表述:
GAN(General Adversarial Network)被叫做生成对抗网络,它涉及两个网络:生成器Generator和判别器Descriminator。两个网络在相互对抗的博弈过程中不断学习,最终训练出可以生成接近真实分布的模型。
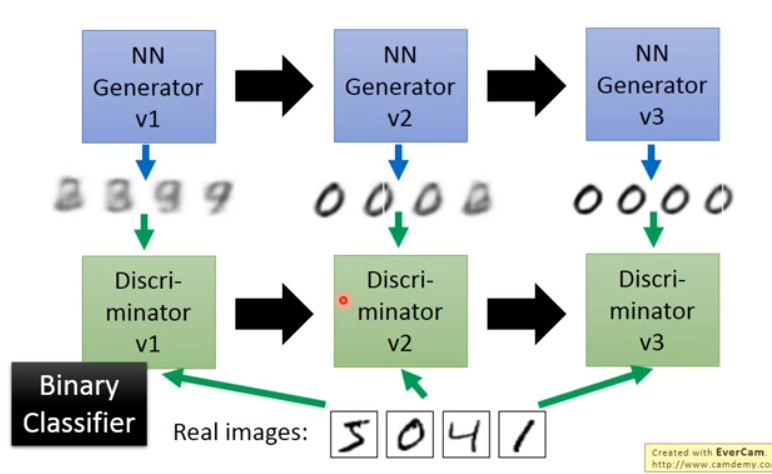
一开始生成器只能生成很模糊的图像,但是判别器效果也很差,所以我们训练一轮判别器直到判别器能够分辨出生成的图像和原来的图像。然后我们训练一轮生成器,直到上一轮的判别器无法分辨出真假。之后再训练判别器,生成器,判别器…如此循环往复,直至判别器再也分辨不出真假,我们就说生成模型已经足够“好“了。
GAN给出了模型优化的目标,公式如下:
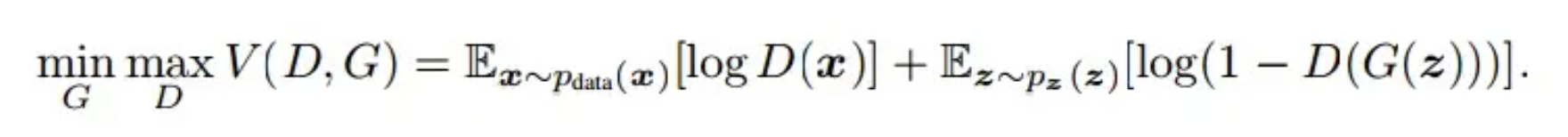
其中,
推导发现,

模型训练的算法如下:

注意首先循环k次训练判别器,用随机梯度上升的方法,最大化目标函数,更新判别器参数;然后随机梯度下降最小化损失函数,更新生成器参数,如此反复迭代到指定次数即可。
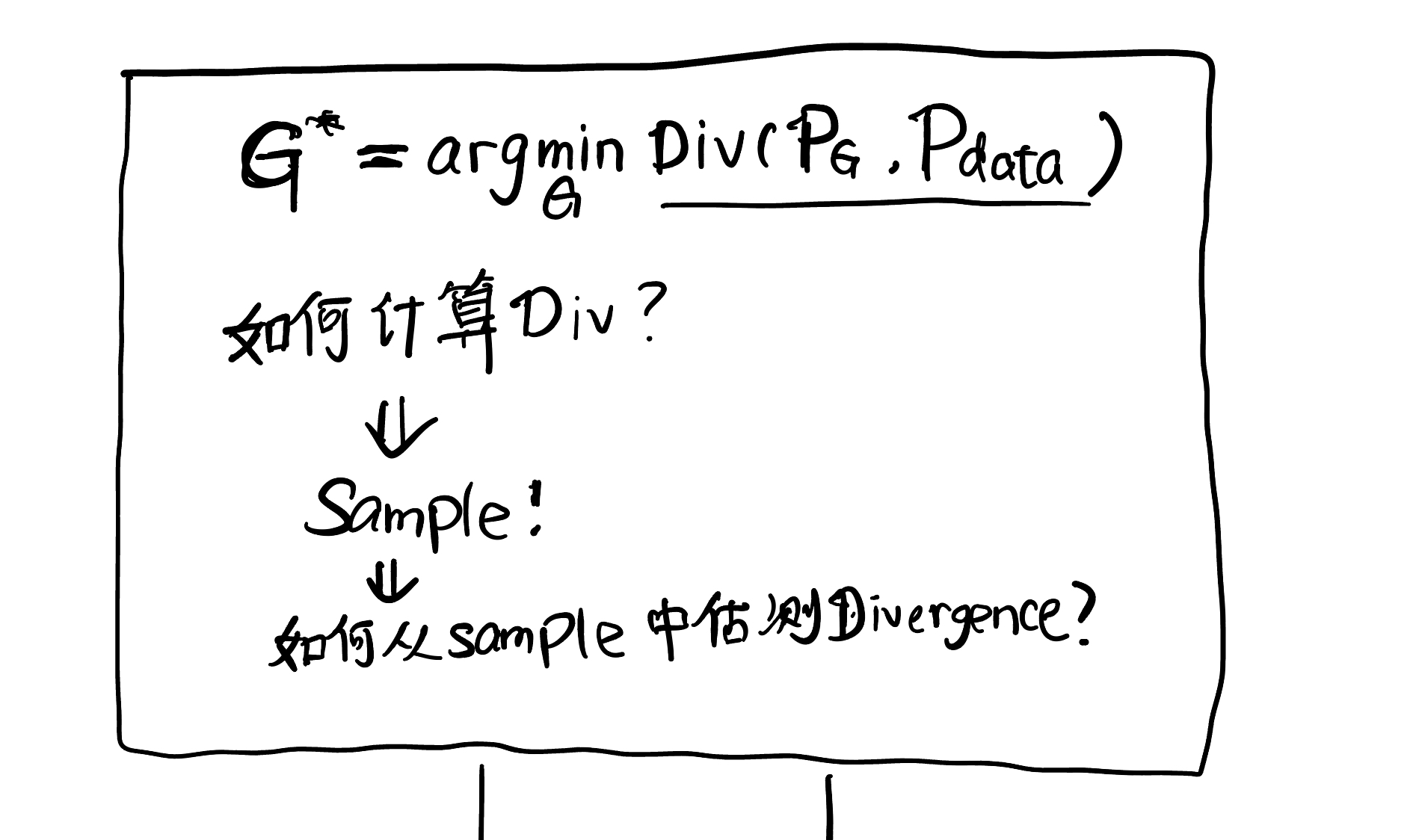
WGAN原理
用JS divergence作为分布之间衡量差异的标准是不合适的,理由如下:
大概率不重合, 都是在高纬度下的低维流形,重合概率非常地小 GAN是从真实分布里取样,生成器也是从高斯分布中选取噪声,更是降低了取到重合数据的概率

JS divergence有一个很重要的性质:除非两个分布重合,不然不管间隔多远,计算出来的divergence都是
来看看一种新的距离:Wasserstein distance
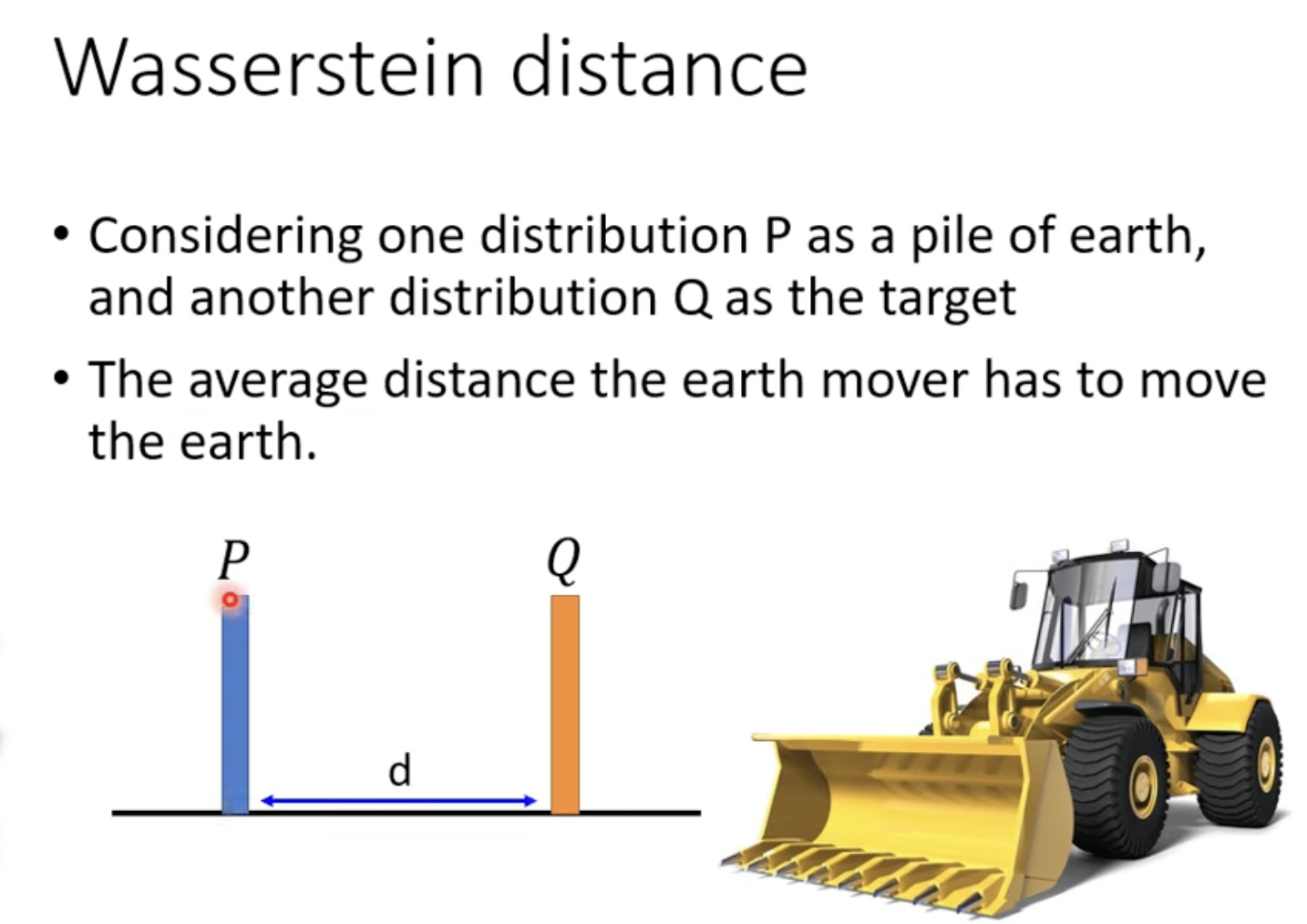
想象一个推土机,要把一堆土从P推到Q,平均要移动的距离d就是Wasserstein distance。当有多个推土计划时,我们就穷举所有的计划,找到其中最小的平均距离作为我们的Wasserstein distance。数学表达式如下:
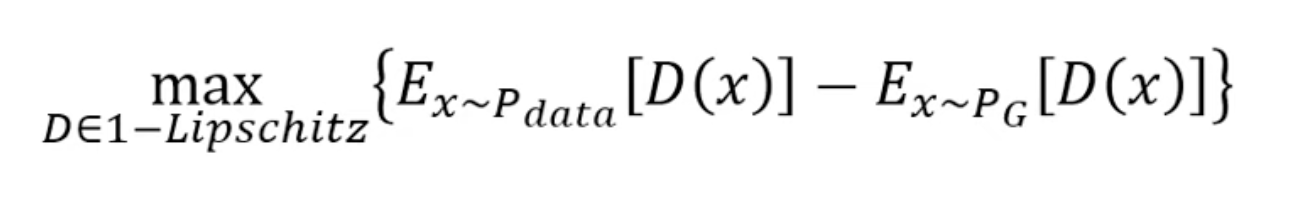
其中D必须属于1 - Lipschitz,换句话说D必须尽可能地平滑。那么如何更好地说明D足够平滑呢?围绕这个问题有许多论文提出了方法,比如Improved WGAN, Improved improved WGAN, Spectral GAN。
Conditional GAN
目的:加上一些条件信息,使得我们能够指定生成的内容。训练目标变为:
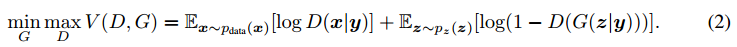
应用1 文本生成图片
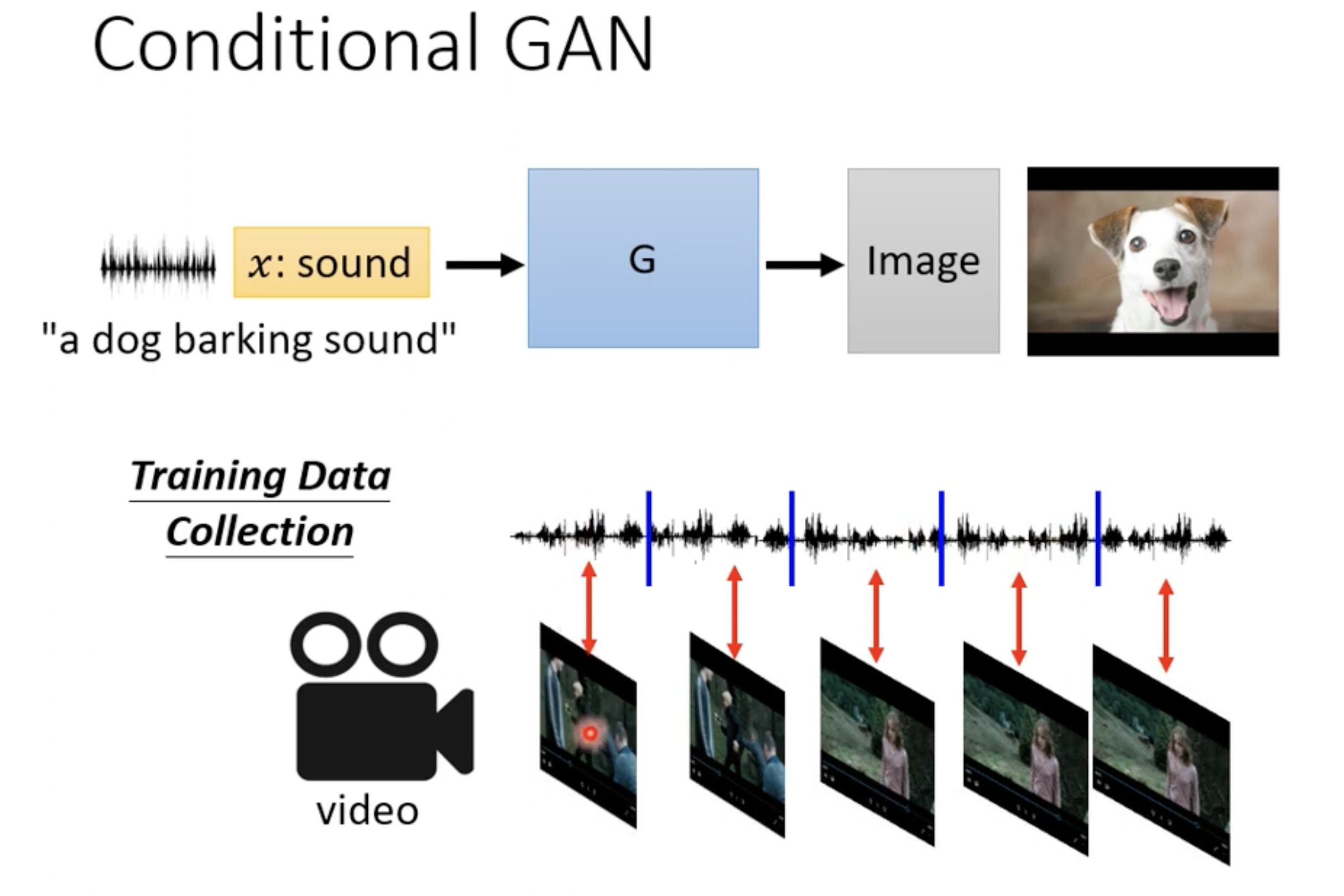
核心是训练出一个好的判别器,能够不止判断生成的图片的真实性,还能够判别文字标签和生成的图像符不符合。为此我们需要有监督地学习<标签,图像>对的判别,这个学习过程不仅要事先有监督地学习,还要在生成的过程中将标签和生成的图像成对进行训练。
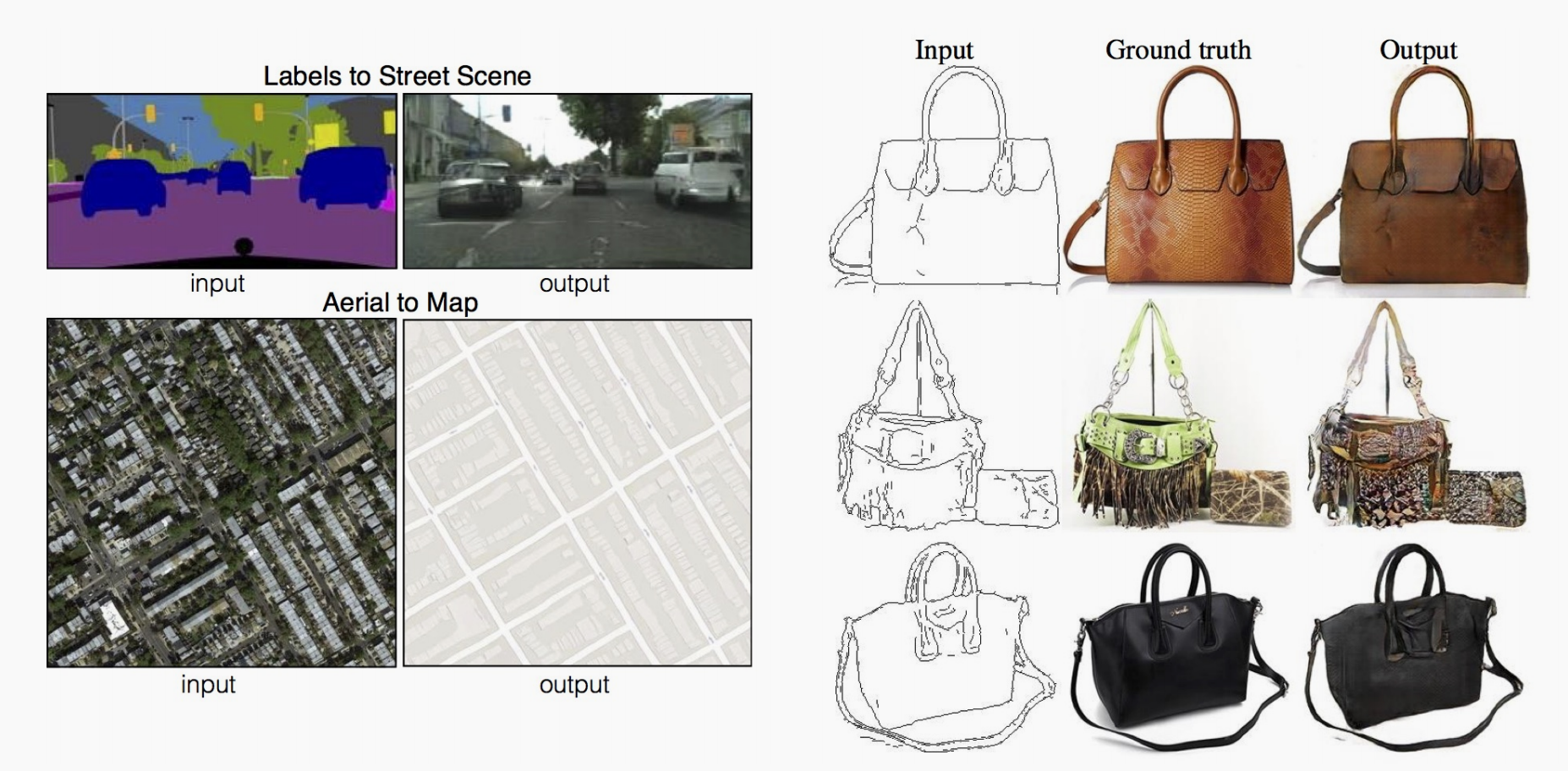
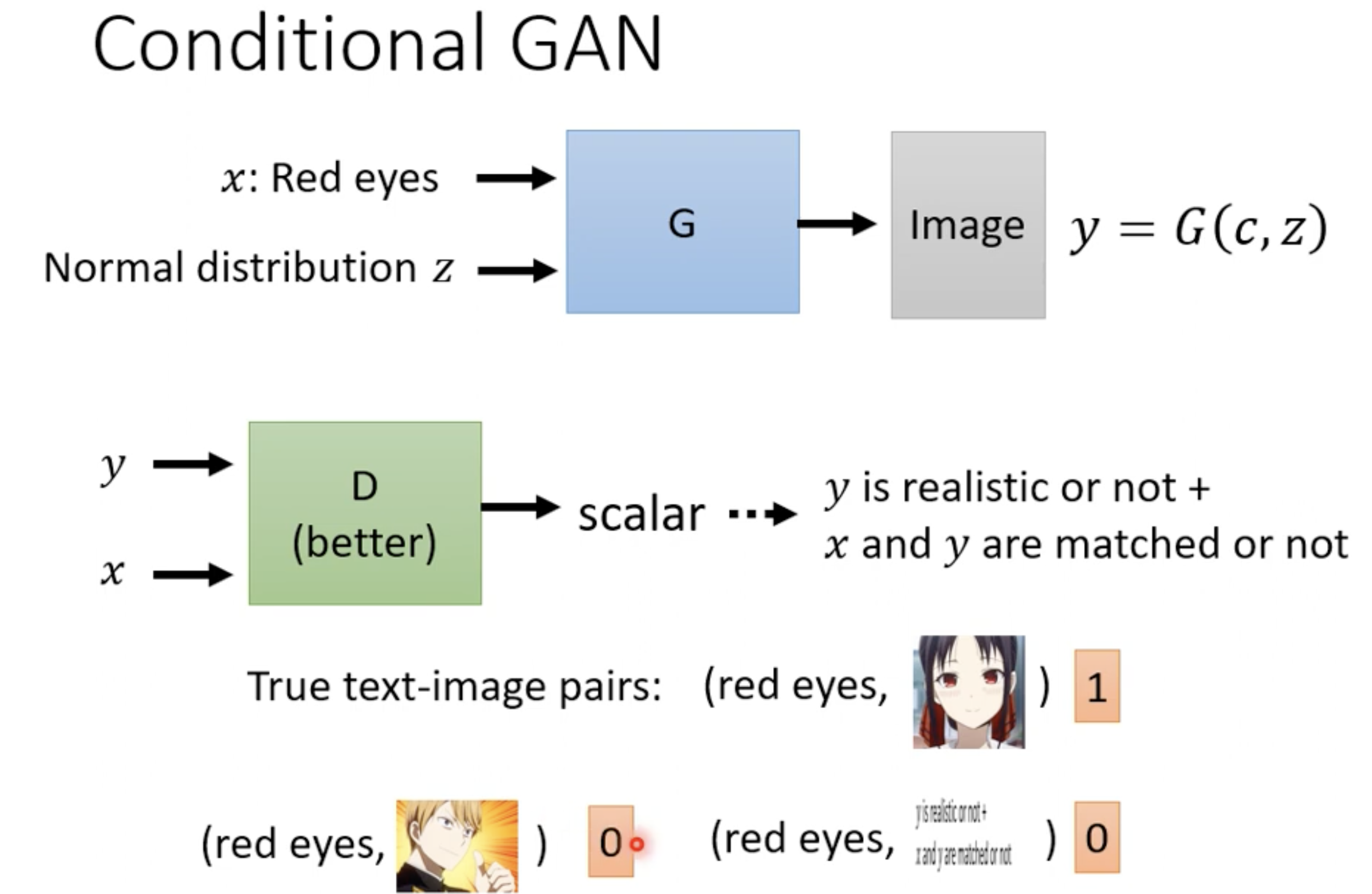
应用2 图片生成图片
又叫Image Translation,比如给定图片线稿生成填色后的图片。原理和文本生成图片类似。
应用3 音频生成图片